프론트엔드 파트 MonoRepo 도입
안녕하세요. 프론트엔드 개발자 박준형입니다.
우리 팀은 현재 각각 독립된 저장소를 가진 멀티레포 방식으로 프론트엔드 제품을 관리하고 있습니다. 이로 인해 개발자들이 불편함을 겪고 있고, 코드의 중복과 관리 비용이 증가하고 있는 상황입니다.
그래서 이 글을 쓰게 되었습니다. 저는 기술적 부채로 느꼈던 멀티레포 방식과 멀티레포라서 방치되어가고 있는 몇몇 프로젝트를 모노레포로 통합하여 관심도를 높이는 문화적 의의를 제공하고자 합니다.
멀티레포에서는 각 프로젝트가 독립적으로 운영되어 개발자들이 공통 코드를 공유하거나 수정하기가 어려웠습니다. 또한, 프로젝트 간의 일관된 관리와 배포가 번거로웠습니다. 이러한 문제들을 해결하고, 개발자들이 더 나은 협업과 개발 환경을 경험할 수 있도록 모노레포로의 전환을 통해 발전된 관리 방식을 도입하고자 합니다.
도입 배경
안녕하세요. 프론트엔드 개발자 박준형입니다.
현재 프론트엔드 제품은 각자의 Repository를 갖고있는 멀티레포 방식으로 관리되고 있습니다. 각각의 제품은 운영방식과 라이프사이클이 모두 다르게 관리되고 있습니다.
독립적인 관리포인트를 갖는 멀티레포 방식은 프로젝트의 완전한 독립성을 보장한다는 장점을 갖고 있습니다. 하지만 각각의 관리포인트를 갖고 있기 때문에 개발자들의 불편함도 함께 다가오고 있다고 우려되었습니다.
물론 긴밀한 의사소통과 미팅과 같은 추상적인 공유를 통해 관리포인트의 문제를 해결할 수 도 있습니다. 하지만 물리적으로 공유도 하며 추상적인 공유도 함께 한다면 의사소통의 비용도 절감되지 않을까라는 생각을 하게 되었습니다.
예를 한번 들어보겠습니다.
프로젝트 A와 프로젝트 B 는 이미 출시가 되어있는 서비스입니다. 신규 서비스인 프로젝트 C 를 만들어야 하는 상황에서 프로젝트를 빌딩하는 과정을 한번 생각해봅니다. 만약 프로젝트 C의 특정기능이 프로젝트 A에서 사용하고 있는 비디오 플레이어의 기능과 유사하다고 판단되어 컴포넌트와 여러 헬퍼함수 모듈을 개발자가 직접 코드를 복사하고 붙여넣기를 하는 작업을 수행하게 됩니다. 이런 경우 직접적인 공유가 아닌 간접적인 공유입니다.
제품마다 배포전략과 브랜치 전략을 픽스하며 문서로 마련하고, 이러한 브랜치 전략 까지 하나의 코드베이스에서 관리를 한다면, 전략이 표준화되고 업무 프로세스까지 마련되어 정신적인 스트레스 또한 사라지지 않을까하여 모노레포를 도입하게 되었습니다.
모노레포를 도입하여 얻게되는 이점
- 비슷한 제품군을 하나의 저장소에서 관리
- 공통 모듈, 헬퍼, 유틸 함수를 함께 사용이 가능합니다.
- 서로 의존적인 패키지의 리팩토링 비용 감소
- 신규 제품 프로젝트를 생성할 때마다 발생하는 오버헤드 절감
- 레포지토리 생성 → 커미터 생성 → 개발환경 세팅 → CI/CD 구축 → 빌드 → publish 과정 생략
- 관리포인트가 단일화
- 코드 스타일 통일화
- 커미터 생성에서 린트 및 프리티어 설정을 하는데 레포지토리 기준으로 룰을 정하니 스타일 통일화 기대할 수 있다.
- 한 조직이 개발했지만 한 사람이 개발한 것과 같은 퀄리티의 코드 스타일 통일성을 기대할 수 있습니다
모노레포를 도입하여 우려되는 점
- 기존에 사용중인 GitFlow 브랜치 전략 사용 불가
- 서비스마다 develop브랜치와 main 브랜치를 만들기에는 현실적으로 어려움
- 테스트 및 빌드 범위
- 소스 변경시 모든 프로젝트를 다시 빌드하거나 다시 테스트하지 않으며 영향을 받는 프로젝트만 다시 테스트하고 빌드해야한다.
도입하며 얻게되는 이점과 우려지점은 도구를 선택한뒤 해결하기로하고, 우선 어떤 패키지 매니저와 모노레포 툴을 사용할지 고려를 하게되었습니다.
패키지 매니저 비교
모노레포를 도입하며 패키지 매니저도 바꾸어 보자는 생각과 함께 비교를 해보기로 했습니다.
기존의 프론트엔드에서 패키지 매니저로 Yarn Classic을 사용했습니다. Yarn Classic이란 Yarn 1.x 버전을 지칭합니다. 성능면에서 다소 느릴 뿐만 아니라 의존성 중복 저장 문제를 해결하기 위해 호이스팅 방법을 사용합니다. 그렇다면 어떤 문제가 존재하는지 알아야 합니다.
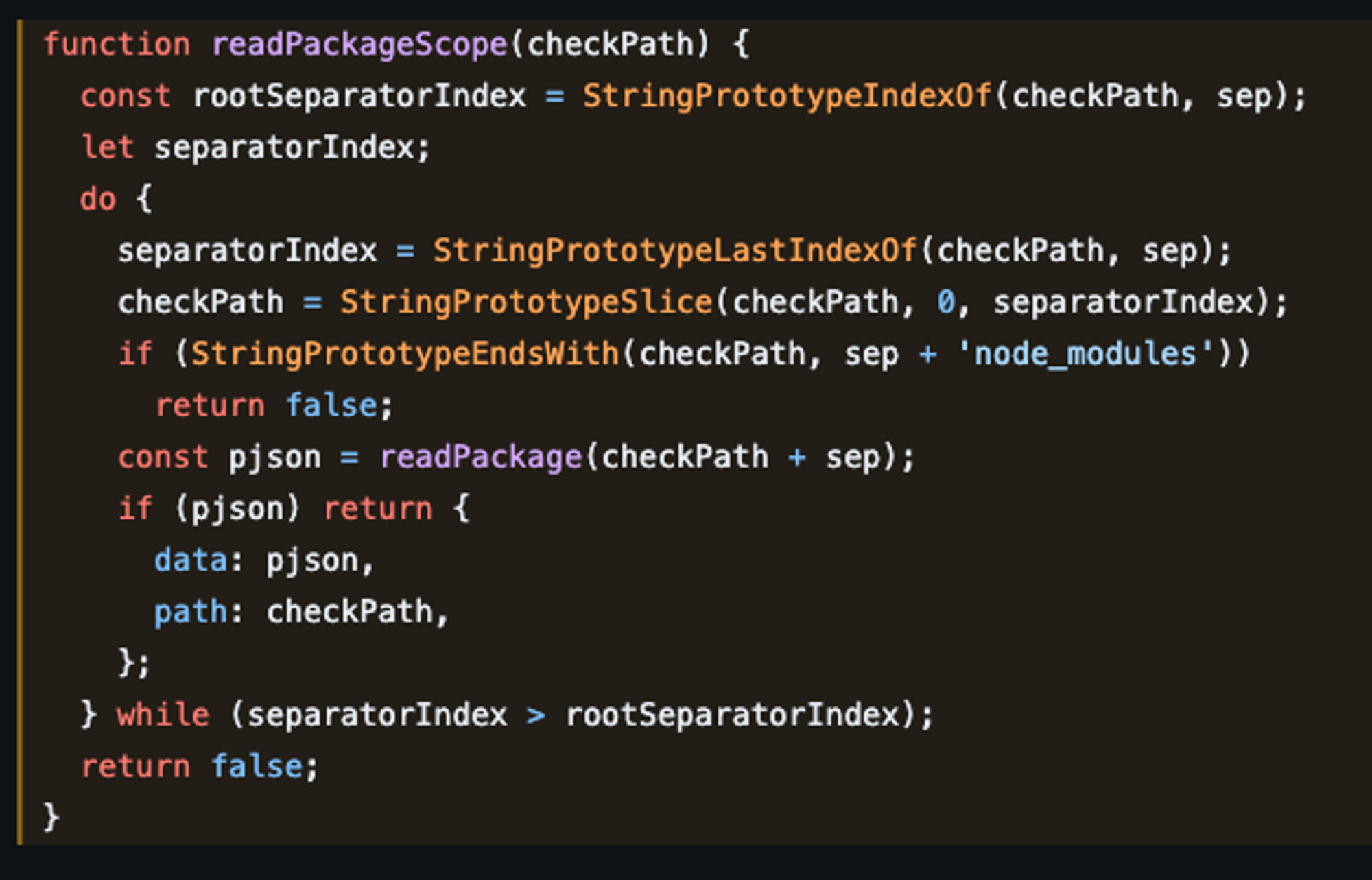
-
node_modules의 문제점
- node.js에서 require 함수를 실행하면 모듈을 찾을 때까지 상위 디렉토리를 순회하는데 이때 느린 Disk I/O 동작이 경로의 깊이만큼 발생하게 됩니다.
-
저장공간과 설치시간
- node_modules는 매우 큰 공간을 차지합니다. 용량만 많이 차지한다면 다행입니다. 디렉토리 구조를 만들기 위해서 많은 I/O 작업이 필요합니다.
- 복잡한 폴더 구조이기 때문에 설치가 유효한지 검증하기 어렵습니다. 수백 개의 패키지가 서로를 의존하는 복잡한 의존성 트리에서 디렉토리 구조는 깊어집니다.
- 디스크 I/O 호출은 메모리의 자료구조를 다루는 것보다 훨씬 느립니다.
-
유령의존성
-
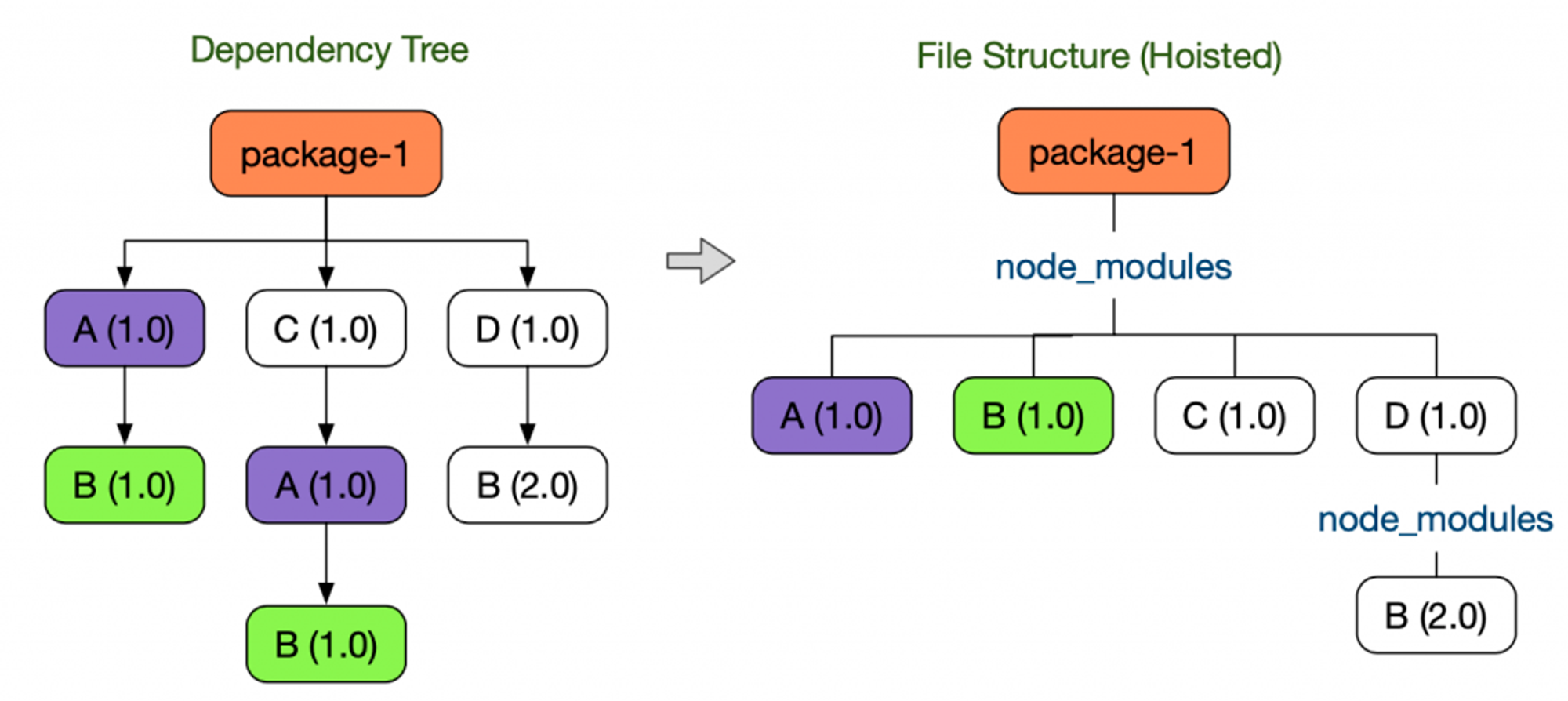
왼쪽 트리에서 A와 C 패키지는 B 패키지를 의존성을 띠게 되는데 A와 C를 설치하며 B를 두 번 설치하게 되어 디스크 공간 낭비를 하게 됩니다.
- 이때 package-1에서는 직접 require(’B’) 가 불가합니다.
-
이를 해결하기 위해 오른쪽 트리처럼 원래의 트리의 모양을 바꿉니다.
- 이렇게 되면서 package-1에서 직접 require(’B’)가 가능해졌습니다.
- 직접의존하지않는 라이브러리를 require할수있는 현상을 유령 의존성이라고합니다.
- 이는 package.json에서 제거했을때 소리없이 사라지며 의존성관리 시스템을 혼란스럽게 만듭니다.
-
이를 해결할 수 있는 방법은 크게 두 가지입니다. Yarn Berry와 Pnpm입니다. Yarn Berry는 Plug’n Play 전략을 통해 중복 저장 문제를 해결하며 호이스팅 방법을 사용하지 않는 것이 기본값입니다. 하지만 저희가 선택한 패키지 매니저는 Pnpm입니다.
선택한 이유부터 말하면, 뒤에서 선택하게 된 TurboRepo에서는 현재까지 Yarn Berry의 Plug’n Play를 지원하지 않기 때문입니다. Pnpm이라는 선택지가 남았으며, Pnpm의 매력을 찾기로 했습니다.
패키지 매니저 벤치마킹
아래의 테이블은 pnpm 문서에서 제공되는 패키지 파일 설치 속도 비교 벤치마킹 입니다
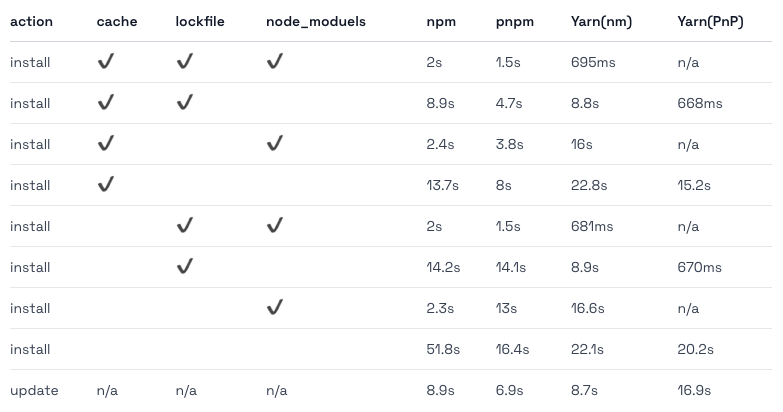
cache가 있는 경우에는 초록색, 없는 경우에는 노란색으로 구분했습니다. Yarn(PnP)는 선택지에 없으므로 배제하고 보시면 됩니다.
각각의 케이스 별로 보더라도 pnpm을 사용한 사례가 성능상 빠르기 때문에 좋은 선택지가 될 수 있다고 생각했습니다.
그렇다면 Pnpm은 중속성 중복 저장 문제를 잘 해결하는지가 궁금합니다.
pnpm의 node_modules 레이아웃은 심볼릭 링크를 사용하여 중첩된 종속성 구조를 만듭니다. node_modules 내의 모든 패키지의 모든 파일은 Content-addressable Store 에 대한 하드 링크입니다. bar@1.0.0에 종속된 foo@1.0.0을 설치한다고 가정했을 때 하기 구조처럼 하드 링크합니다.
node_modules
└── .pnpm
├── bar@1.0.0
│ └── node_modules
│ └── bar -> <store>/bar
│ ├── index.js
│ └── package.json
└── foo@1.0.0
└── node_modules
└── foo -> <store>/foo
├── index.js
└── package.json
위의 구조는 실제로 설치되는 node_modules의 형태입니다. 그래프 구조를 구축하기 위해 심볼릭 링크가 생성됩니다.
두 패키지는 모두 node_modules 폴더 내의 하위 폴더에 하드 링크 되어 있습니다. 이러한 하드 링크 구조는 패키지가 스스로를 가져올 수 있도록 허용합니다. foo는 require(’foo/pacakage.json') or import * as package from “foo/package.json”로 가져올 수 있어야 합니다.
다음은 종속성 심볼릭 링크로 bar는 foo@1.0.0/node_modeuls에 심볼릭 링크됩니다.
node_modules
└── .pnpm
├── bar@1.0.0
│ └── node_modules
│ └── bar -> <store>/bar
└── foo@1.0.0
└── node_modules
├── foo -> <store>/foo
└── bar -> ../../bar@1.0.0/node_modules/bar
심볼릭 링크는 중복 저장 문제를 해결하기 위해서 사용하는 방법입니다. 심볼릭 링크는 하나의 파일에 대한 여러 개의 링크를 허용하여 디스크 공간을 절약합니다.
심볼릭 링크를 사용하면 같은 파일을 여러 번 저장할 필요가 없어 디스크 공간을 절약할 수 있습니다. 여러 번 저장할 필요 없이 하나의 파일만 저장되고, 필요한 곳에서 해당 파일로 링크를 걸어 사용하는 방식입니다.
중복 저장 문제는 주로 대규모 프로젝트나 여러 프로젝트에서 같은 파일을 사용하는 경우 발생합니다. 예를 들어, 여러 모듈이 동일한 종속성을 가지는 경우, 각 모듈이 해당 종속성을 각각 저장하면 디스크 공간이 낭비됩니다. 심볼릭 링크를 사용하면 각 모듈이 동일한 종속성을 참조할 수 있어 디스크 공간을 절약할 수 있습니다.
결론적으로, 심볼릭 링크는 중복 저장 문제를 효과적으로 해결하여 디스크 공간을 절약하고, 패키지 관리 및 설치 속도를 향상시킬 수 있습니다.
이를 통해 pnpm이 중복 저장 문제를 잘 해결하고 있다는 것을 확인할 수 있었습니다.
터보레포
TurboRepo의 주요 미션은 모노레포 환경에서 개발자가 조금 더 쉽고 빠르게 개발할 수 있도록 빌드 도구를 제공하는것입니다.
Content-aware-hashing
- 타임스탬프가 아닌 콘텐츠를 인식하는 방식으로 해싱을 지원합니다.
- 모든 파일을 다시 빌드하는게 아니라 변경된 파일만 빌드합니다.
Pruned subsets
모노레포는 락파일을 전역으로 관리합니다. 프로젝트 A 워크스페이스와 프로젝트 B 워크스페이스가 있습니다. 프로젝트 B의 디펜던시가 변경된다면 전역 락파일에 반영됩니다.
디펜던시가 변경되지않은 프로젝트 A 워크스페이스를 도커로 빌드할때 락파일이 변경된것을 보고 새로 디펜던시를 설치하기 시작할것입니다.
락파일을 전역으로 사용하기 때문에 문제라면 빌드할 워크스페이스만 떼어내 락파일을 도커에게 전달해주면 편하지않을까요?
├── apps
| ├── 프로젝트 A // design-system, 프로젝트 A-oas 사용
| | ├── src/..
| | ├── package.json
| |
| ├── 프로젝트 B // design-system, 프로젝트 B-oas 사용
| ├── src/..
| ├── package.json
|
├── packages
| ├── design-system
| | ├── src/..
| | ├── package.json
| |
| ├── 프로젝트 A-oas
| | ├── src/..
| | ├── package.json
| |
| ├── 프로젝트 B-oas
| ├── src/..
| ├── package.json
|
├── pnpm-lock.yaml // 전역 락 파일!
위와 같은 구조로 되어있다고 가정하고 프로젝트 B을 빌드해야하는 상황이라고 가정해봅시다. 프로젝트 B 패키지는 design-system과 프로젝트 B-oas 패키지만 사용중입니다.
터보레포를 사용하지않고 workspace 필드만을 사용해서 Docker 이미지를 만들어야하는 상황을 생각해봅시다.
Dockerfile (Prune 사용 X)
FROM node:18-alpine AS base
FROM base AS builder
WORKDIR /app
COPY . .
FROM base AS installer
WORKDIR /app
# 필요한 패키지들을 복사
COPY --from=builder /app/apps/프로젝트 B/ . ./apps/프로젝트 B
COPY --from=builder /app/package/design-system/ . ./package/design-system
COPY --from=builder /app/package/프로젝트 B-oas/ . ./package/프로젝트 B-oas
# 여기서 문제 발생!
COPY --from=builder /app/out/pnpm-lock.yaml ./pnpm-lock.yaml
# 패키지 설치
RUN pnpm install
# Build the project
WORKDIR /app/apps/프로젝트 B
RUN pnpm build
# Stand Alone 설정으로 Runner Stage
FROM base AS runner
# 중간 생략
CMD node apps/프로젝트 B/server.js
어찌저찌해서 필요한 패키지들을 빌드와 인스톨 스테이지에 모아왔다고 가정해봅시다. 하지만 모노레포 빌드 환경에서 락파일은 전역에 존재합니다. 락파일은 가지치기가 되어있지않아 빌드타겟인 프로젝트 B 패키지의 의존성만 설치되는것이 아니라 불필요한 의존성까지 설치될것입니다.
이는 또 잠재적으로 도커 이미지 빌드에 사용될 워크스페이스와 관련 없는 의존성 변경으로 캐시 miss를 야기할수도있습니다.
이런문제를 터보레포도 진작에 파악하고있고 Prune이라는 기능을 제공해줍니다.
turbo prune --scope="프로젝트 B” 라고 CLI 명령어를 입력하면 아래와 같은 결과물을 얻습니다.
├── apps
| ├── 프로젝트 B // design-system, 프로젝트 B-oas 사용
| ├── src/..
| ├── package.json
|
├── packages
| ├── design-system
| | ├── src/..
| | ├── package.json
| |
| ├── 프로젝트 B-oas
| ├── src/..
| ├── package.json
|
├── pnpm-lock.yaml // 가지치기된 전역 락 파일!
무엇이 달라졌는지 눈에 보이시나요? 프로젝트 B과 관련된 패키지들만 가지치기가 되었습니다. 하지만 제가 우려했던것은 전역 락파일을 불필요한 의존성 문제였죠?
아래의 사진은 전역 락파일과 prune 기능으로 만들어낸 가지치기된 락파일입니다.
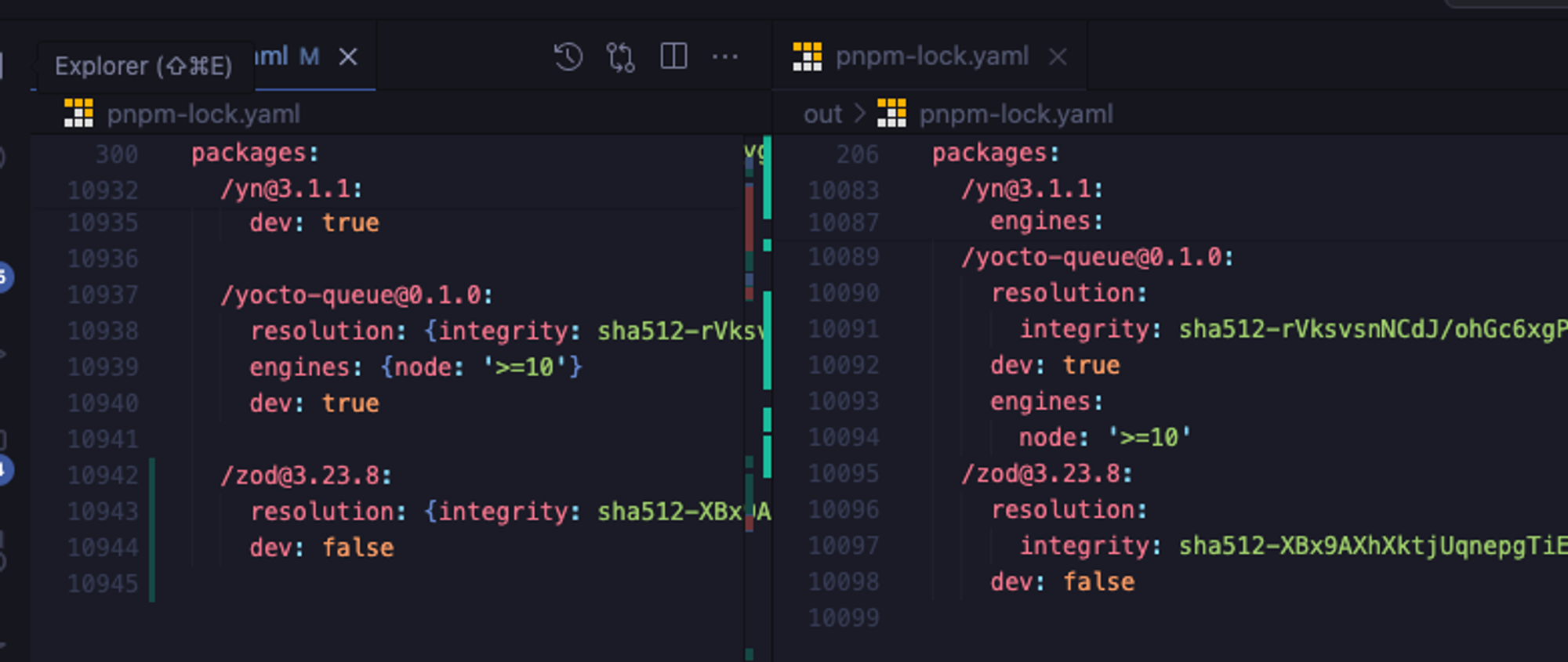
무려 900줄이나 차이가 존재합니다. 이로써 프로젝트 B과 관련된 패키지들만 락파일에 생성이 되었다는것입니다.
더욱 매력적인것은 —docker 옵션입니다. 이 옵션을 사용하면 아래와 같이 뽑아줍니다.
├── full // 집중!!
| ├── apps
| | ├── 프로젝트 B
| | ├── src/..
| | ├── package.json
| |
| ├── packages
| ├── design-system
| | ├── src/..
| | ├── package.json
| |
| ├── 프로젝트 B-oas
| ├── src/..
| ├── package.json
|
├── json // 집중!!
| ├── apps
| | ├── 프로젝트 B
| | ├── package.json
| |
| ├── packages
| ├── design-system
| | ├── package.json
| |
| ├── 프로젝트 B-oas
| ├── package.json
|
├── pnpm-lock.yaml
full 디렉터리에서 package.json 파일만을 가져와서 만들어진 json 디렉터리라는점이 눈에 보입니다.
Install Stage(JSON) → Build Stage(Full) → …
이제 Install Stage에서 의존성 설치에 필요한 pnpm-lock.yaml과 package.json 만을 가질수 있게 되었고, 더이상 의존성과 관련되지않은 파일의 변경으로 캐시가 miss되는 일은 생기지 않을것입니다.
Cloud caching
- 클라우드 빌드 캐시를 팀원 및 CI/CD의 환경인 Github actions와 공유합니다.
- 로컬환경을 넘어 클라우드 환경에서도 빠른 빌드를 제공합니다.
아래의 사진은 각각 컴퓨터에서 캐시가 로컬로 저장되는 상황입니다. 이를 클라우드 캐시로 올려서 불필요한 중복작업을 제거 해볼 수 있습니다. 터보레포는 기본적으로 로컬 파일 시스템에만 캐시를 저장하므로 모든 작업 입력이 동일하더라도 동일한 작업(빌드, 린트, 테스트)을 각 머신에서 다시 실행해야 하며, 이는 명백한 리소스 낭비입니다.
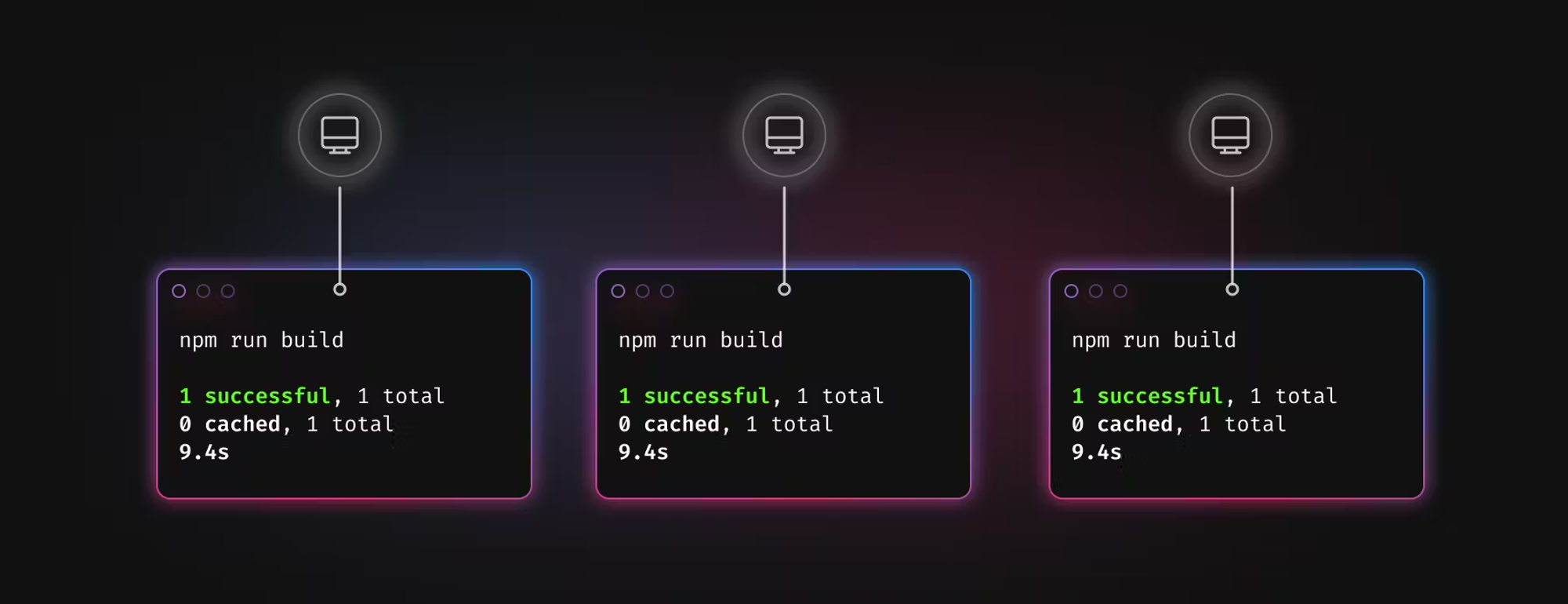
팀원들과 그리고 CI환경에서도 하나의 캐시를 공유할 수 있다면 조직 전체에서 중복 작업을 방지하여 시간을 절약할것입니다.

리모트 캐시 API 제작
터보레포에서는 리모트 캐시를 사용하기 위해서는 API 사양을 충족하는 모든 HTTP 서버에서 구현할 수 있다고 안내합니다. Vercel에서 제공하는 원격캐시를 사용할 수 도있지만, 굳이 Pro나 Enterprise 요금제를 사용하기가 껄끄럽기도하며 데이터의 안전을 위해 안전한 API 서버를 만들기로 합니다.
turborepo-remote-cach에서 제공해주는 소스코드를 사용하면됩니다.

fastify를 기반으로 구성되어 미리 구현되어있는 엔드포인트를 통해 따로 작업없이 서버를 띄우는것만으로도 원격캐싱이 지원되며, 현재 사용중인 Google Cloud Storage서비스를 사용할 수 있습니다.
커스텀 캐시 서버를 구축하는 과정은 다음과 같습니다.
- turborepo-remote-cach에서 소스코드를 클론합니다.
- Storage-Provider를 위한 설정 및 기타 환경변수를 입력합니다.
- Docker Image를 만들어 Cloud Run과 같은 서버리스 호스팅 서비스에서 제공합니다.
커스텀 캐시 서버를 구축했으니 커스텀 캐시를 사용하는 방법은 굉장히 간단합니다.
Turborepo의 루트 디렉토리에 .turbo/config.json 파일을 생성하여 아래와 같은 정보를 입력합니다.
- teamid : 커스텀 캐시 서버의 teamid를 기입합니다.
- token : 커스텀 캐시 서버의 token를 기입합니다.
- apiurl : 커스텀 캐시 서버의 Url을 기입합니다.
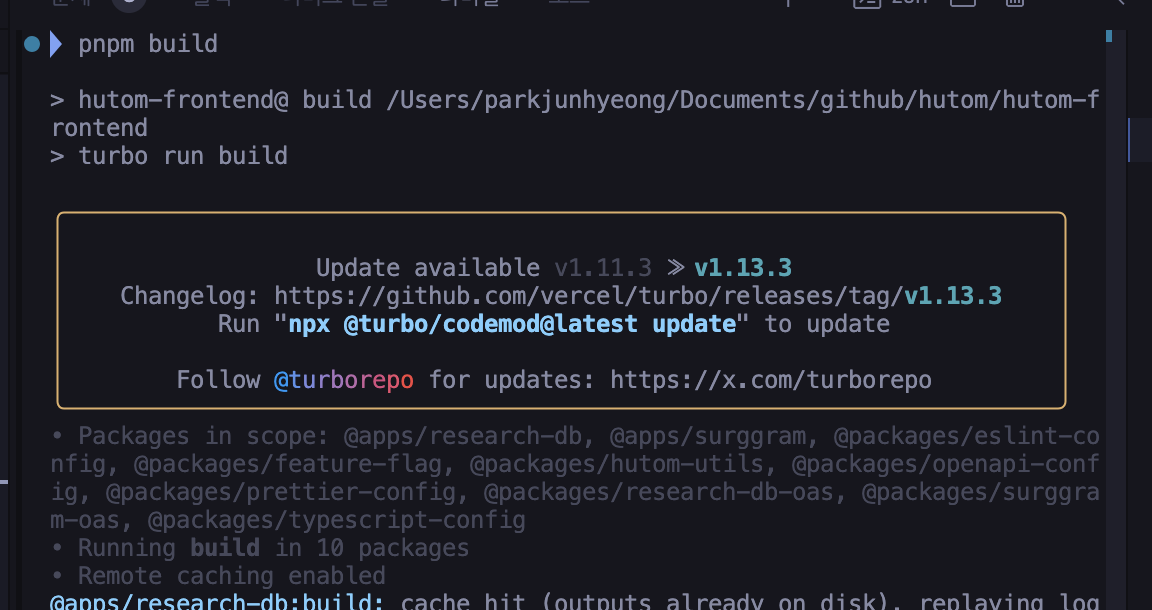
마지막 줄을 보면 Remote caching enabled라는 문구가 있습니다! 이로서 리모트캐시를 제공하는 http 서버는 생성했습니다.
버전 관리
제품을 이해하기 위해서는 제품의 버전을 먼저 이해해야합니다! 한 제품을 만들기위해 여러부서와 버전의 컨텍스트를 공유합니다.
제품의 통일된 버전 정책을 가지기 위해서는 유의적인 버전을 사용해야합니다. 유의적 버전이란 제품에 버전을 어떻게 부여하고 관리해야하는지에 대한 규칙입니다.
유의적버전을 사용하지만 여러 유관부서와 협업을 해야하기때문에 pre-release-version과 pre-release-code가 일반적인 유의적버전과는 다르게 사용하고있습니다.
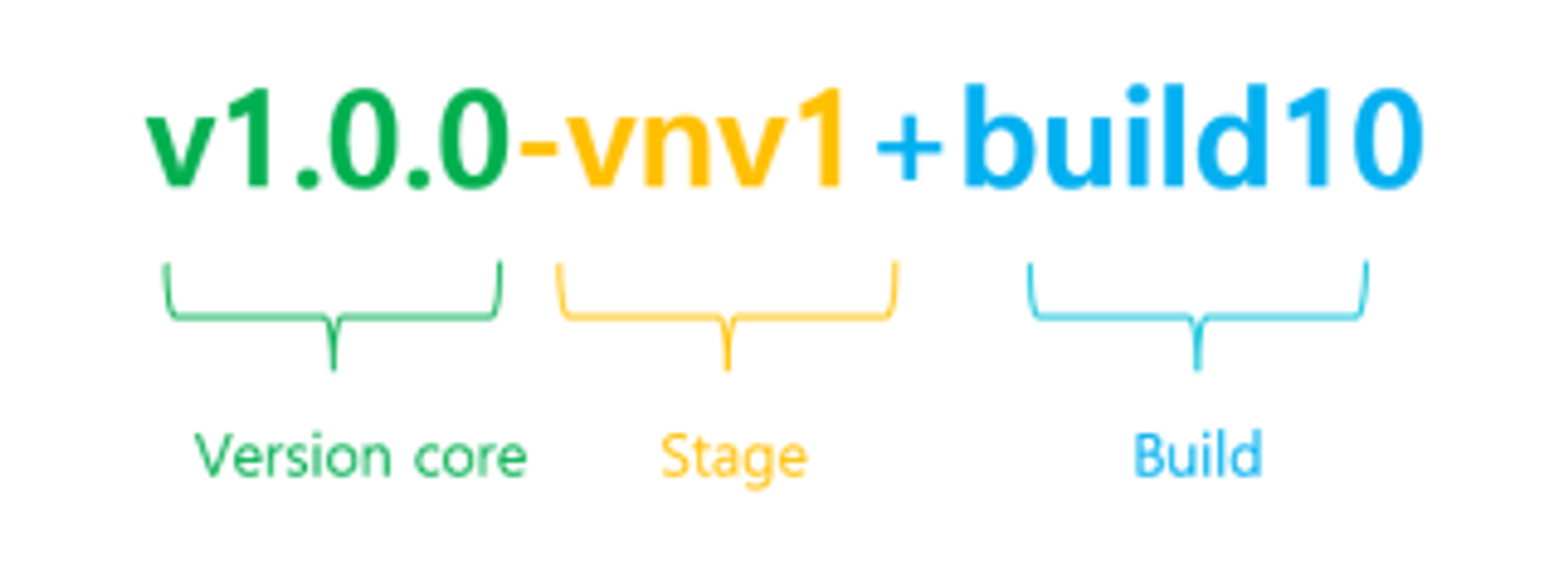
- major, minor, patch 은 유의적버전과 동일하게 사용합니다 🙂
- major, minor, patch는 PM팀에서 정해주어 모든 부서가 공유하는 버전입니다.
- stage는 구현단계와 시스템 테스트 단계에서 주로 사용합니다.
- 구현단계 : patch 버전 뒤에
-dev를 붙여 사용하며 몇번째 단계인지 숫자로 표기합니다.- ex)
v1.0.0-dev1,v1.0.0-dev2,v1.0.0-dev3
- ex)
- 시스템 단계 : V&V팀에서 테스트를 진행하는 단계로 구현단계와 마찬가지의 컨벤션을 따릅니다.
- ex)
v1.0.0-vnv1,v1.0.0-vnv2
- ex)
- stage가 반복적으로 이루어지는 경우 stage뒤에 숫자를 붙여 사용합니다.
- 구현단계 : patch 버전 뒤에
- build는 PLT 팀이 stage에서 몇번째 빌드했는지를 명시합니다.
- build 정보는 자연수로 표기하며 stage가 변경되어도 build 숫자는 초기화 하지 않습니다.
- ex)
v1.0.0-vnv1-build1,v1.0.0-vnv1-build2,v1.0.0-vnv2-build3
브랜치 전략 비교
Git Flow
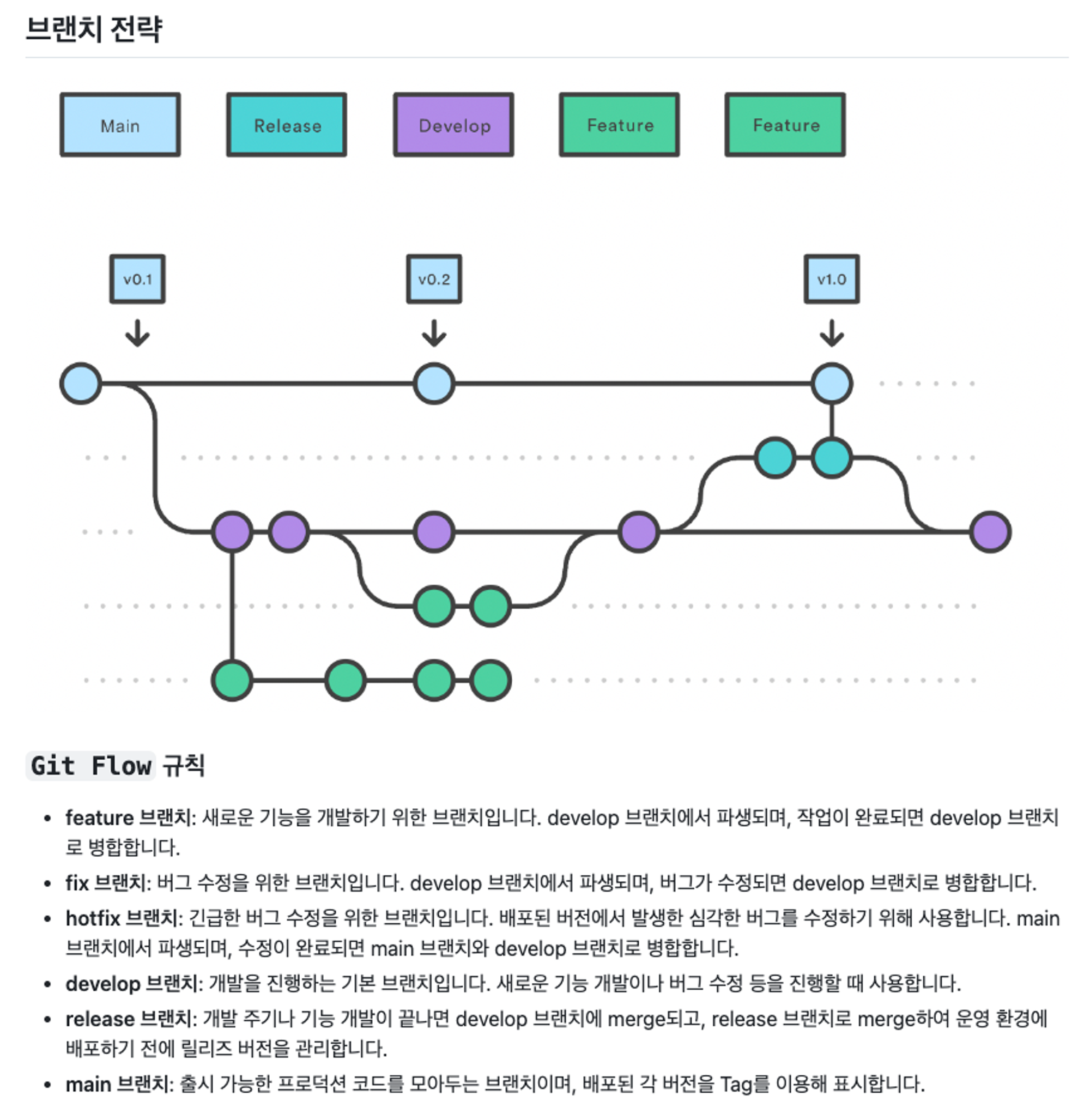
위의 그림은 기존에 사용하던 GitFlow 전략입니다. 각각의 프로젝트는 각각 배포 주기가 다를수도있으며, 운영방식이 다르기 때문에 이에 맞춰 유연하게 사용할 수 있어야합니다.
Git Flow 는 왜 모노레포에서 사용하기 어려운가
모노레포에서는 GitFlow로는 복잡성 문제를 해결하기 어렵습니다.
- 복잡성 증가
- 모노레포는 여러 프로젝트를 하나의 저장소에서 관리하기 때문에 복잡합니다. GitFlow는 브랜치 관리전략이 복잡한데 여러 프로젝트의 다양한 브랜치를 관리하기에는 부적절합니다.
- 동기화 문제
- GitFlow는 feat, develop, main 브랜치 등을 통해 작업을 합니다. 모노레포에서는 여러 프로젝트의 브랜치가 서로 연관되어 서로 영향을 줄 수 있어 동기화가 어렵습니다.
- 릴리즈 관리의 어려움
- 모노레포에서는 여러 프로젝트가 동시에 릴리즈 되는 경우가 많습니다. GitFlow는 개별 프로젝트의 릴리즈를 관리하는데는 적합하지만 여러 프로젝트를 관리하는 모노레포에서는 릴리즈를 조율해야 하므로 릴리즈 병목이 발생할 수 있습니다.
Trunk-Based Development
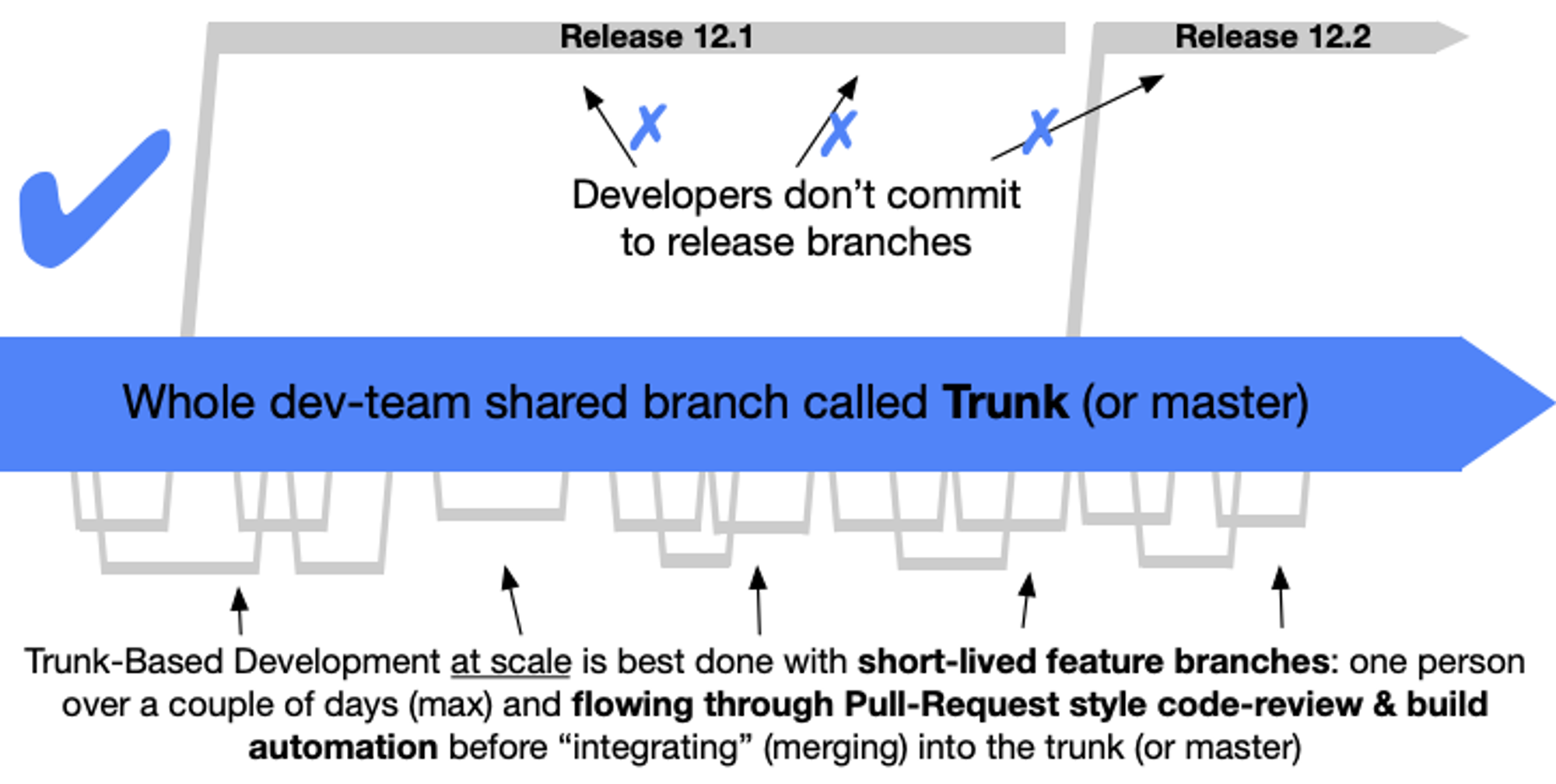
Trunk-Based Development 란 소스 제어 도구에서 브랜치를 어떻게 관리할지에 대한 전략입니다. 개발자들은 마스터에서 협업하고, 긴 작업 단위의 브랜치 생성을 피해야합니다. 그렇게 함으로서 협업 간 충돌을 최소화하고 빌드가 실패되는 상태를 막습니다.
이 모델의 가장 주요한 특징은 트렁크라 불리는 마스터 브랜치를 항상 배포 가능한 올바른 상태로 유지하는 것이고 이를 보장하기 위한 주요 규칙은 다음과 같습니다.
개발규칙
-
브랜치 푸시로 개발 진행
- 개발 작업은 모두 브랜치 푸시를 통해 이루어집니다.
-
브랜치 푸시란?
- Trunk 브랜치에서 새로운 피쳐 브랜치(Feature)를 생성합니다. -Feature 브랜치에서 작업을 완료한 후, Pull Request(PR)를 통해 Trunk 브랜치로 스쿼시 머지합니다. 스쿼시 머지는 여러 커밋을 하나로 합쳐서 머지하는 것을 의미합니다.
-
직접 푸시 금지
- 개발 중에는 Trunk 브랜치나 다른 브랜치에 직접 푸시하는 것을 허용하지 않습니다.
- 반드시 Feature 브랜치를 사용해 작업하고, PR을 통해 머지해야 합니다.
-
PR 올린 후 Trunk 브랜치가 업데이트되고 해당 브랜치에 반영해야 하는 경우
- 작업 중인 브랜치에서 git merge trunk 로 반영합니다.
-
작업 단위의 크기
-Feature 브랜치는 가능한 한 작은 작업 단위로 나눠서 작업합니다. 작은 단위로 나누면 코드 리뷰가 쉽고, 버그 발생 시 문제를 빠르게 찾을 수 있습니다.
-
장기간 작업에 대한 규칙
- 장기간 지속되어야 하는 큰 기능 개발의 경우, 피쳐 플래그와 인터페이스를 사용해 작업 단위를 나눕니다.
- 피쳐 플래그는 특정 기능을 켜고 끌 수 있는 설정을 말하며, 이를 통해 단계적으로 기능을 개발하고 배포할 수 있습니다.
- 인터페이스를 사용해 모듈화된 작업을 수행함으로써 다른 기능에 영향을 최소화합니다.
배포 규칙
-
브랜치 만들기
- Trunk 브랜치에서 Release 브랜치를 생성합니다
- Trunk 브랜치는 기본 개발 브랜치입니다. 새로운 릴리즈를 준비할 때는 Trunk 브랜치에서 Release 브랜치를 만듭니다.
-
변경 사항 적용하기
- Release 브랜치에서 변경이 필요할 때, Trunk 브랜치의 커밋을 cherry-picking 합니다
- Release 브랜치에서 수정이나 새로운 기능 추가가 필요하면 Trunk 브랜치에 있는 커밋을 선택적으로 가져와서 Release 브랜치에 적용합니다(cherry-picking).
- 중요한 점: Trunk 브랜치에 없는 커밋은 Release 브랜치에 포함되어서는 안 됩니다. 즉, Trunk 브랜치에 없는 변경 사항이 Release 브랜치에 존재해서는 안 됩니다.
-
핫픽스 처리
- 핫픽스도 동일한 방식으로 처리합니다
- Release 브랜치에서 버그 수정(hotfix)이 필요할 때도 Trunk 브랜치에서 cherry-picking으로 커밋을 가져와서 적용합니다.
-
릴리즈 완료 후 버전 태깅
- 릴리즈 완료 후 버전 태그를 달아야 합니다
- 버전 태깅은 릴리즈가 완료된 커밋에 특정 버전 번호를 부여하는 것입니다.
- 만약 cherry-picking이 발생하지 않은 경우: Trunk 브랜치에 있는 커밋에서 태깅을 합니다.
- 만약 cherry-picking이 발생한 경우: 해당 Release 브랜치의 최종 커밋에서 태깅을 합니다.
프로젝트마다 배포 주기가 다를수도있으며, 운영방식이 다르기 때문에 이에 맞춰 유연하게 사용할 수 있어야합니다.
이에따라 기존의 GitFlow를 버리고 새롭게 Trunk Based Development(TBD) 로 해결해보려합니다.
이를 위해 Feature Flag를 먼저 도입해야합니다.
Feature Flag
사용자에게 보이는 기능을 동적으로 토글 할 수 있는 스위치로 서비스 중인 앱에 새로운 기능을 추가하거나 변경할 때 그 변경사항을 일부 사용자에게만 보이게 하거나 숨기는데 사용할 수 있습니다.
피처플래그의 보편적인 사용방법은 사용자들에게 실험적 혹은 제한된 기능을 제공하는데 사용됩니다.
애플리케이션에는 버전이 존재합니다. 피처플래그가 제한된 기능을 제공한다는것에서 영감을 받아 버전에따라 기능의 범위를 제한하도록 피처플래그를 설계해보는 방법을 떠올리게되었습니다.
버전에 따라 기능제공의 여부를 선택하도록 Feature Flag 를 설계해보자
프로젝트 B을 만들어가는 PLT팀과 유관부서들이 있습니다.
PM팀에서 Core Version(v0.1.0)을 정해주고 기능의 범위를 정해줍니다. (로그인기능을 예시로 설명합니다)
PLT팀은 정해진 Core Version에 맞게 구현 단계에 들어가게됩니다. 그렇게 v0.1.0-dev1 버전이 탄생합니다.
export const 프로젝트 B_VERSION_0_1_0_DEV1 = {
로그인: FeatureFlag.onDevelopment({
// 구현단계이므로 개발환경에서만 제공합니다.
key: 'login',
description: '로그인 기능',
}),
} as const
v0.1.0-dev1의 피처플래그를 만듭니다. 여기서 확인할것은 세가지입니다. 현재 기능이 개발환경, 스테이징환경, 운영환경에 배포가 되어도 되는 상태인지 아닌지를 확인합니다.
v0.1.0-dev1는 구현단계이므로 development만 true로 만들어놓습니다.
v0.1.0-dev1에서 무언가 문제가있어 보완하기위해 v0.1.0-dev2 버전이 탄생합니다.
// monorepo/packages/feature-flag/프로젝트 B/v0.1.0-dev2.ts
export const 프로젝트 B_VERSION_0_1_0_DEV2 = {
...프로젝트 B_VERSION_0_1_0_DEV1,
} as const
바로 아래 버전인 v0.1.0-dev1 의 피처플래그를 가져와서 구조분해할당해줍니다. 윗버전은 하위버전의 기능을 모두 포함해야하기때문입니다. 만약 하위버전의 기능중 변경되어야하는것이 있다라면 기능의 키의 값을 변경해주면됩니다. v0.1.0-dev2 에서는 v0.1.0-dev1 와 비교해 달라진게없으므로 그대로 가져갑니다.
v0.1.0-dev2 로 구현단계가 완료되었습니다. v0.1.0-vnv1-build1 버전이 탄생합니다.
// monorepo/packages/feature-flag/프로젝트 B/v0.1.0-vnv1-build1.ts
export const 프로젝트 B_VERSION_0_1_0_VNV1_BUILD1 = {
...프로젝트 B_VERSION_0_1_0_DEV2,
로그인: FeatureFlag.onStaging({
// V&V 검증단계이므로 개발, 스테이징 환경에서만 제공합니다.
key: 'login',
description: '로그인 기능',
}),
} as const
검증단계에 들어왔으니 스테이징환경에서 제공해야합니다. 그래서 로그인 피처플래그의 staging 속성을 true로 변경하였습니다.
1차 검증단계에서 수정이 필요해서 v0.1.0-vnv1-build2 버전을 만들어 변경합니다. 이후 다시 V&V팀에게 2차 검증을 요청하기 위해 v0.1.0-vnv2-build3 버전을 만들어서 제공합니다.
// monorepo/packages/feature-flag/프로젝트 B/v0.1.0-vnv2-build3.ts
export const 프로젝트 B_VERSION_0_1_0_VNV2_BUILD3 = {
...프로젝트 B_VERSION_0_1_0_VNV1_BUILD2,
} as const
v0.1.0-vnv2-build3 의 로그인 피처플래그는 v0.1.0-vnv1-build2 에서 수정했을뿐 공개범위는 달라지지 않았으니 그대로 가져갑니다.
V&V의 2차 검증이 완료된후 버전을 릴리즈해야하는 상황이 왔습니다. 이제 v0.1.0을 릴리즈 합니다.
// monorepo/packages/feature-flag/프로젝트 B/v0.1.0.ts
export const 프로젝트 B_VERSION_0_1_0 = {
...프로젝트 B_VERSION_0_1_0_VNV2_BUILD3,
로그인: FeatureFlag.onProduction({
// V&V 검증이 완료되었으니 개발, 스테이징, 운영환경 모두 제공!
key: 'login',
description: '로그인 기능',
}),
} as const
v0.1.0 은 운영환경에서도 제공이 되어야합니다. 그러므로 로그인 기능의 production 속성을 true 로 변경해줍니다.
이렇게 버전에 따라 달라지는 공개범위에대한 피처플래그 설계는 완료되었습니다. 그렇다면 어떻게 써야하는지를 알아봐야합니다.
// monorepo/packages/feature-flag/프로젝트 B/index.ts
export const LAST_VERSION_FEATURE_FLAG = 프로젝트 B_VERSION_0_1_0
// scope의 undefined는 Production에서 쿼리스트링이 없을 때를 대비한 default 값입니다.
export const IS_ENABLED_FEATURE_FLAG = (
key: keyof typeof LAST_VERSION_FEATURE_FLAG,
scope: 'development' | 'staging' | undefined
) => {
const featureFlag = FeatureFlag.findByFeatureFlagKey(LAST_VERSION_FEATURE_FLAG, key)
return FeatureFlag.isEnabledByScope(featureFlag, scope || 'production')
}
// monorepo/apps/프로젝트 B/src/(pages)/login/page.tsx
export default function LoginPage({ searchParams }: Props) {
if (!IS_ENABLED_FEATURE_FLAG('로그인', searchParams.scope)) {
redirect('/')
}
return <div>로그인 페이지</div>
}
위 부터 아래로 한번 알아보겠습니다.
LAST_VERSION_FEATURE_FLAG- development / staging / production 피처플래그의 정보가 담겨있는 최신화된 버전의 피처플래그입니다.
IS_ENABLED_FEATURE_FLAGLAST_VERSION_FEATURE_FLAG의 특정 피처플래그가 특정 환경에서 제공 가능한 상태인지 확인하는 함수입니다.
이렇게 @packages/feature-flag/프로젝트 B 패키지에서 제공된 피처플래그 정보로 @apps/프로젝트 B 애플리케이션 패키지에서 기능의 제공 여부를 열고 닫아줍니다.
TBD + Feature Flag
TBD는 Trunk 브랜치에서 협업하며, 긴 작업단위의 브랜치 생성을 피합니다. 그렇게 함으로서 협업 간의 충돌을 최소화하며 빌드가 실패하는 상태를 막습니다. 가장 중요한것은 Trunk 브랜치는 항상 배포가 가능한 올바른 상태로 유지하는것입니다.
이 말은 즉 Trunk라는 단일브랜치에서 개발환경 / 스테이징환경 / 프로덕션환경 모두 배포가 가능한 올바른 상태로 유지를 해야한다는 말이 됩니다.
그래서 피처플래그에 개발환경 / 스테이징환경 / 프로덕경환경에서 사용 가능한 상태인지를 체크하는 플래그를 심어줬던것입니다.
피처플래그 기능이 페이지단위에서 꺼져있다면 루트페이지로 리다이렉트하고, 컴포넌트단위에서 꺼져있다면 보이지않도록 정의하면됩니다.
이제 어떻게 지속적으로 제공하며 안정적으로 테스팅했는지 next.js 14버전 기준으로 소개하겠습니다.
우선 피처플래그에게 현재의 환경이 어느환경인지 어떻게 제공할지를 생각해보다가 환경변수로 Scope를 제공해주면 되겠다는 생각을했습니다. 그리고 런타임에 어떻게 프론트엔드 서버에 주입을 시킬지를 생각했습니다.
프론트엔드의 서버는 웹서버이므로 HTTP Request를 받습니다. 그리고 프론트엔드의 서버는 Next.js로 만들어져있습니다. 그래서 Next.js에서 제공하는 미들웨어를 사용하기로 하고 문서를 읽어보았습니다.
- Path Rewriting: Support A/B testing, feature rollouts, or legacy paths by dynamically rewriting paths to API routes or pages based on request properties
- Feature Flagging: Enable or disable features dynamically for seamless feature rollouts or testing.
훌륭합니다! 미들웨어에서 사용하는 방법이 유즈케이스라고 소개하고있고 이제 미들웨어를 제어하면됩니다.
export async function middleware(req: NextRequest) {
const url = req.nextUrl.clone()
switch (env.SCOPE) {
case 'development': {
if (!url.searchParams.has('scope')) {
url.searchParams.set('scope', 'development')
return NextResponse.redirect(url)
}
break
}
case 'staging': {
if (!url.searchParams.has('scope')) {
url.searchParams.set('scope', 'staging')
return NextResponse.redirect(url)
}
break
}
case 'production': {
if (url.searchParams.has('scope')) {
url.searchParams.delete('scope')
return NextResponse.redirect(url)
}
break
}
}
return NextResponse.next()
}
Next.js의 미들웨어는 요청이 완료되기 전에 코드를 실행할 수 있습니다. 요청에 따라 요청 또는 응답 헤더를 재작성하거나 리다이렉션 혹은 수정할 수 있습니다.
그렇게 개발환경과 스테이징환경에서는 스코프를 쿼리파람즈로 제공하고, 운영환경에서는 실제 유저가 쿼리파람즈가 없이도 사용이 가능하도록 스코프를 제거한채 제공합니다.
개발환경에서 basePath로 접근한경우 자동으로 스코프가 쿼리파람즈로 붙게됩니다! 이렇게 피처플래그를 서버에게 제공해주고있는것까지 완료했습니다.
그러면 이제 안정적으로 피처플래그가 동작하고있는지 테스트하기위해 테스트코드를 작성하도록 합니다.
// 현재 개발중인 버전
export const 프로젝트 B_VERSION_0_1_0_DEV1 = {
로그인: FeatureFlag.onDevelopment({
key: '로그인',
description: '로그인 기능',
}),
} as const
// 로그인 페이지
const LoginPage = ({ searchParams }: Props) => {
if (!IS_ENABLED_FEATURE_FLAG('로그인', searchParams.scope)) {
redirect(`/`)
}
return <div>로그인 페이지</div>
}
로그인 페이지의 기능제공범위는 아래와같다고 상황을 가정해 봅니다.
- 개발환경 :
**On** - 스테이징환경 :
**Off** - 프로덕션환경 :
**Off**
이를 시나리오로 E2E테스트 도구인 Cypress의 도움을 받아 테스트 케이스를 작성해 봅니다. 피처플래그를 테스트하는 E2E테스트는 패키지의 **/cypress/e2e/feature-flags** 폴더에서 관리하도록 해두었습니다.
describe('Login FeatureFlag 테스트', () => {
it('development 환경에서는 화면이 보인다.', () => {
cy.visit('/login?scope=development')
cy.location().should((location) => {
expect(location.pathname).to.eq('/login')
})
})
it('staging 환경에서는 랜딩페이지로 리다이렉트된다.', () => {
cy.visit('/login?scope=staging')
cy.location().should((location) => {
expect(location.pathname).to.eq('/')
})
})
it('production 환경에서는 랜딩페이지로 리다이렉트된다.', () => {
cy.visit('/login')
cy.location().should((location) => {
expect(location.pathname).to.eq('/')
})
})
})
각 케이스에맞게 시나리오대로 케이스를 작성하였습니다.
